Coursera week 4 Machine Learning: Regression
1. Characteristics of overfit models
전에 배웠던 bias 와 variance 간의 trade-off 관계에 대해 심층적으로 다룰 것이다.
어떻게 trade-off 관계에서 sweet spot 이라는 점에 도달해
가장 좋은 퍼포먼스를 낼 수 있는 예측을 할 수 있는가?
이것이 이번 모듈에서 이뤄야 할 목표 중 하나이다.
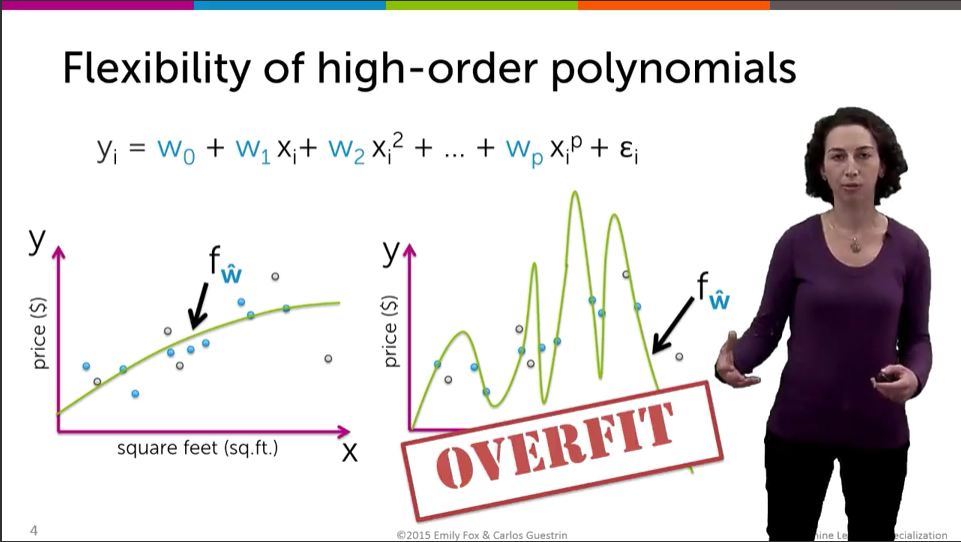
간략히 설명하자면,
bias 와 variance 에 의해 complexity가 결정이 되는데
high complexity를 갖게 되면 overfit이 발생한다.
high complexity 함수를 구해서 트레이닝 셋의 에러 확률을 줄였지만(Overfit)
테스트 셋에서 분명 높은 에러률을 보일 것이다.
반대로 low complexity 함수를 구하면
두개의 셋에서 높지 않은 확률을 보일 경우가 많을 것이다.
그러므로 complexity를 잘 조절해서 전자와 후자의 장점을 잘 뽑아 낼수만 있다면
좋은 퍼포먼스를 갖는 함수를 만들 수 있을 것이다.
즉, overift 은 bias 와 variance 간의 trade-off 관계를 잘 조절하면 해결 할 수 있다는 것이다.
그렇다면 어떻게 조절해야하는가?
이 모듈에서는 그 해결책으로 Ridge Regression을 제시한다.
해결책을 익히기 전에 현상에 대한 이해가 필요하다.
Ridge Regression 을 모른다고 가정할 때, overfit에 영향을 주는 요소들은 무엇인가?

우선 소량의 데이터는 overfit 을 야기한다.

그리고 input의 수가 많아질 수록 overfit을 피하기 어렵다.

또한 예측 함수의 계수가 엄청 크면 overfit하다고 할 수 있다.
2. The ridge objective
이제 overfit을 해결하기 위해 하나씩 풀어나가 보자.
우선 cost function 을 전에 쓰던 것과 달리할 필요가 있다.
방금 얘기했듯이 함수의 계수가 높으면 overfit하다고 했다.
전 게시글에는 cost function이 아마 RSS 하나로 측정했을 것이다.
하지만 overfit을 방지하기 위해
이번에는 계수에 대한 식을 더해 cost function을 만든다.

위와 같은 식이 된다.
두 개 요소 간의 밸런스가 중요하다.
우선 전에 배웠던 RSS인 measure of fit에 대해 알아보자.

그리고 이제 처음 공부하는 measure of magnitude of coefficient에 대해 알아보자.

어떻게 계수에 대한 식을 표현해야할까에 대한 답이다.
첫번째는 그냥 다 더하는 것이다.
그럼 음수값 때문에 정확도가 떨어진다.
두번째는 절대값을 더하는 것이다.
L1 norm 이라고 한다.
나쁘지 않지만 마지막 것이 더 좋은 듯하다.
마지막으로 절대값을 제곱해 더하는 것이다.
L2 norm 이라고 한다.
L2 norm을 이용해 cost function을 만들어 앞으로 수업한다고 한다.
이제는 저 두 값중 measure of magnitude of coefficient를 조절해가면서
어떻게 변화되는지 알아보자.

여기서 람다는 유저가 조절하는 tuning parameter이다.
람다가 0일 때와 무한대 일때와 두 값 사이일 때를 비교하고 있다.
그렇다면 람다가 0일 때와 무한대 값일 때 bias와 variance 를 비교해보자.

작은 람다는 old version 의 cost function이기 때문에 RSS 밖에 존재하지 않는다.
그렇다면 높은 복잡도를 보일 것이고 overfit이 발생할 것이다.
반대로 큰 람다는 높은 bias 와 낮은 variance를 갖게되 낮은 복잡도를 보일 것이다.
너무 큰 람다는 w(hat)을 0으로 수렴시킨다.
두 개를 종합해 보면 람다는 복잡도를 조절할 수 있다는 것을 알 수 있다.

overfit을 줄이는 여러 관계들을 종합해 Ridge regression이라고 한다.
L2 regularization이라고도 한다.
즉, 여러 관계의 중심에 있는 람다를 조절(regularization)하는 것을 Ridge regression이라고 할 수 있겠다.

위 코드는 리스트 안에 있는 람다값들을 하나씩 넣어 그래프를 그려보는 코드이다.
l2_penalty값이 바로 우리가 그토록 조절하고 싶은 람다이다.
저 코드에 나오는 graphlab 라이브러리는 다운받는 것이 복잡하다..
대체재로 scikit learn에는 ridge regression 함수 안에 alpha 라는 파라미터가
그 역할을 하는 듯 하다.
다음 코드에는 가장 좋은 l2_penalty를 찾는 코드 또한 존재한다.
하지만 올리기 힘드니 그냥 코세라 사이트에 보면 ipynb 링크가 존재한다.

람다의 크기에 따른 w(hat)의 계수 값을 그래프로 나타내고 있다.
람다가 작을 때는 엄청 큰 계수를 갖지만
람다가 점점 커질 수록 계수가 0으로 수렴한다는 것을 알 수 있다.
그렇다고 무조건 람다가 큰 것이 좋은 것은 아니다.
우리의 목표는 sweet spot을 찾는 것이다.
너무 큰 람다는 이미 sweet spot을 지나갔을 확률이 크다.
3. Optimizing the ridge objective
Step 1 : Rewrite total cost in matrix notation
RSS을 행렬로 구하는 방법은 이미 했고
measure of magnitude of coefficient를 행렬로 구하는 방법을 알아보겠다.

위와 같이 전치행렬을 이용하여 제곱을 구할 수 있다.
Step 2 : Compute the gradient
또한 우리는 ridge regression cost의 gradient를 구해야한다.

gradient 는 위와 같이 그냥 미분값을 구하면 된다.
Step 3 , Approach 1 : Set the gradient 0 ( Ridge closed-form solution )

gradient는 위의 그래프 중 미분값이 0인 값을 찾기 위해 계산했다.
즉, 최소값을 구하기 위해 계산했다고 할 수 있다.
cost function = 0 을 두고 계산하면 위 그림과 같이 식이 나온다.
그리고 람다를 바꾸었을때 값의 변화를 알아야한다.
위의 행렬 I는 고등수학에 배우는 단위행렬이다.
별거 없어 보이지만 람다 계산할 때 꼭 필요하다.

행렬의 곱을 전체적으로 표현하면 위와 같은 그림처럼 표현할 수 있다.
람다가 0보다 크면 단위행렬은 교환법칙이 성립한다.
Step 3 , Approach 2 : Gradient descent

Gradient descent 는 전에도 봤듯이 위 그래프의 중앙에 가기 위해 점점 기울기를 줄여가며
원하는 값에 나아가는 것이다.

위의 왼쪽에 있는 그래프가 중요하다.
원래 old version은 빨간색 펜으로 그려진 것처럼 람다에 대한 식이 없기 때문에 RSS의 gradient값만큼만 더해졌다.
하지만 new version은 람다가 있기 때문에 위와 같이 파란 펜으로 그려진 것처럼
그래프가 그려진다.
y축은 계수의 크기이기 때문에 파란색 펜은 y값이 작아지는 반면
빨간펜은 오히려 커지는 것을 볼 수 있다.
4. Tying up the loose ends
자. 이때까지 람다가 미치는 영향에 대해 알아보았다.
그렇다면 이제 람다는 어떻게 구할 수 있는가?

충분한 데이터가 있지 않다면 validation set에서 람다를 실험해보고 선택한다.
저번에 실습에 있었던 코드를 보면 가장 좋은 L2_penalty 값을 구하는
과정이 validation을 통해 최적의 람다를 구하는 것이다.
더 나아가서 람다를 구하려면 validation 과정이 중요한데 validation을 어떻게 하면 효과적이게 할 수 있는가?
보편적으로 대부분 k-fold cross validation을 사용한다.

위 과정이 굉장히 중요하다.
예를 들어, 5-fold cross validation을 한다고 할 때, 첫번째 블록을 valid set으로 둔 w(hat)lambda(1) 두번째, 세번째, .. , 다섯번째까지를 모두 구해 5로 나는 평균 error 값을
람다별로 비교 후 그 error 값이 가장 작은 람다가 최적의 람다이다.
여기서 error(lambda) 는 전에 배운 total cost 값이다.



댓글
댓글 쓰기