Machine Learning in Action ch.7.1 & 7.2 AdaBoost
6장인 SVM을 다 끝내지 못한 채 7장을 하려니 뭔가 찝찝한 기분이다.
우선 AdaBoost를 쉽게 설명하자면, 당신이 어떤 중요한 결정을 하려할 때, 한 전문가를 신뢰하기 보다 여러 전문가들의 충고를 듣고자 하는 것과 같다.
즉, 메타 알고리즘으로서 서로 다른 알고리즘들을 결합하는 방법 중 하나이다.
우리는 가장 인기가 좋은 메타 알고리즘 중 AdaBoost에 초점을 둘 것이다.

우선 AdaBoost를 쉽게 설명하자면, 당신이 어떤 중요한 결정을 하려할 때, 한 전문가를 신뢰하기 보다 여러 전문가들의 충고를 듣고자 하는 것과 같다.
즉, 메타 알고리즘으로서 서로 다른 알고리즘들을 결합하는 방법 중 하나이다.
우리는 가장 인기가 좋은 메타 알고리즘 중 AdaBoost에 초점을 둘 것이다.
7.1 데이터 집합의 다양한 표본을 사용하는 분류기
위에서 쓴 것처럼 AdaBoost는 메타 알고리즘 혹은 앙상블 메소드라 한다.
오류율이 낮고 코드가 쉽다는 장점이 있다. 그리고 가장 좋은 건 조절을 위한 매개변수가 없다.
아웃 라이어에 민감하다는 단점도 갖고 있다.
7.1.1 배깅 : 임의로 추출한 재표본 데이터로부터 분류기 구축하기
배깅은 다양한 분류기를 통합하는 방법이다.
배깅은 크기가 S인 원본 데이터 집합을 가지고 크기가 S인 다른 데이터집합을 S번 만들게 된다.
S개의 데이터 집합들을 구축하고 나면, 학습 알고리즘은 개별적으로 각각의 데이터 집합에 적용된다.
여기에서는 랜던포레스트처럼 배깅보다 더 발전된 방법을 다룬다.
드디어 랜덤 포레스트가 나왔다.. 캐글에서 자주 쓰이는 알고리즘 중 하나라던데 궁금하다..
7.1.2 부스팅
부스팅은 배깅과 유사한 기술이다. 다만 배깅은 언제나 동일한 유형의 분류기를 사용하는 데 비해 부스팅은 순차적으로 다른 유형의 분류기를 사용한다.
부스팅은 이전 분류기에서 잘못 분류된 데이터에 초점을 맞추어 새로운 분류기를 만든다.
부스팅은 가중치를 부여한 모든 분류기의 합계로 계산하므로 배깅과는 차이가 있다.
가중치에 있어서도 배깅은 이전 반복에서 성공한 분류기를 기반으로 처리하기 때문에 부스팅과는 차이가 있다.
부스팅에는 많은 유형이 있으나 이번에는 AdaBoost를 공부할 것이다.
이제부터 우리는 AdaBoost에 대한 약간의 이론과 이것이 왜 잘 동작하는지에 대해 논한다.
7.2 훈련 : 오류에 초점을 맞춘 분류기 개선
어떻게 약한 분류기와 다양한 사례를 가지고 강한 분류기를 생성할 수 있는가?
여기서 약한 분류기는 오류율이 50%보다 높은 분류기를 뜻한다.
결국 AdaBoost는 천재 한 명의 결과보다 여러 명의 인재들을 모아둔 결과가 더 좋다는 것이다.
AdaBoost는 Adaptive Boosting의 줄임말이다.
모든 약한 분류기들로부터 답을 구하기 위해서 AdaBoost는 각각의 분류기에 알파 값을 부여한다.
알파의 방정식은 위와 같다.
로그 오른쪽에 있는 변수는 오류 값이다.
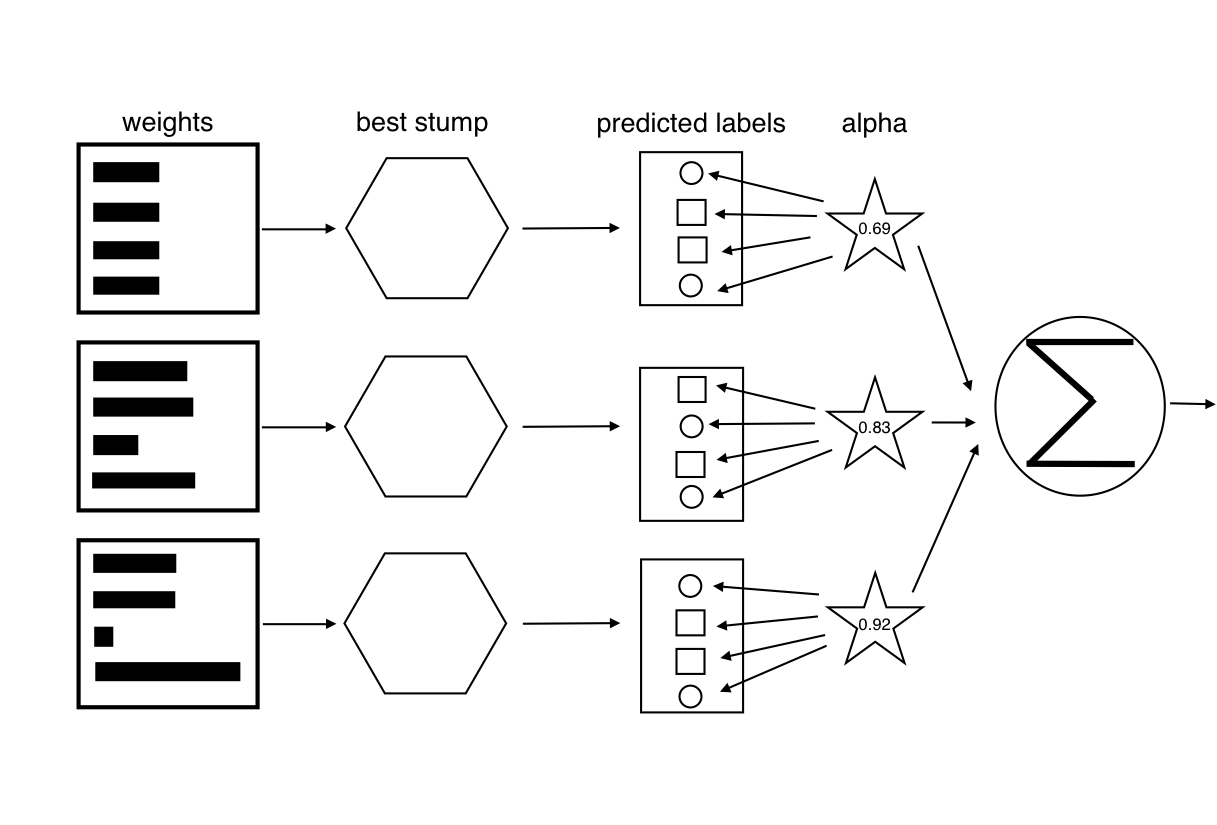
AdaBoost의 알고리즘을 도식적으로 표현한다면 아래와 같다.
가중치 벡터가 계산되고 나면 AdaBoost는 다음 반복을 시작한다. AdaBoost 알고리즘은 훈련 오류가 0이 되거나, 약한 분류기들의 수가 사용자가 정한 값에 도달하기까지 훈련과 가중치 조절을 되풀이한다.
이미지 출처
(https://ko.wikipedia.org/wiki/%EC%97%90%EC%9D%B4%EB%8B%A4%EB%B6%80%EC%8A%A4%ED%8A%B8)
(https://github.com/DrSkippy/Data-Science-45min-Intros/tree/master/adaboost-101)



댓글
댓글 쓰기