Machine Learning in Action ch.3.1 Tree
3.1.2 데이터 집합 분할하기
이제 데이터 집합에서 어수선함을 계산하는 측정 방법을 보게 될 것이다.
분류 알고리즘을 작동하기 위해서는 엔트로피를 측정하고 데이터 집합을 분할하며,
분할된 집합의 엔트로피를 측정하고 분할이 올바르게 되었는지 확인해야 한다.
def splitDataSet(dataSet, axis, value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(reducedFeatVec)
retDataSet.append(reducedFeatVec)
return retDataSet
위 코드에서 .append 와 .extend 는 비슷하지만 완전히 다른 함수이다.
아래의 예제를 보면 이해가 빠를 것이다.

위 분할 함수는 분할하고자 하는 데이터 집합, 분할하고자하는 속성 그리고 반환할 속성의 값을 인자로 갖고 데이터를 분할한다.
이제 데이터 분할 시 가장 좋은 속성을 선택하는 함수를 만들어야한다.
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) -1
baseEntopy = clacShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals =set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i , value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy+=prob*clacShannonEnt(subDataSet)
infoGain = baseEntopy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
위의 함수는 엔트로피를 계산하여 좋은 속성을 골라 리턴한다.
두번 째 조건문에서 majority는 속성이 더 이상 없을 때 가장 많은 수를 반환하는 조건이다.
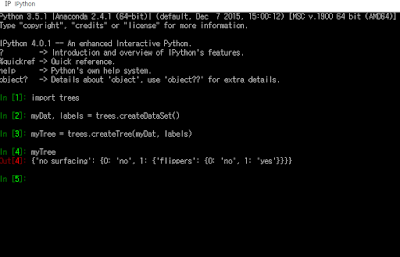
실행시켜 보면 딕셔너리 구조로 만들어진 트리가 출력된다.
다음에는 매스플롯라이브러리를 이용해 시각적인 트리를 플롯해볼 것이다.
이제 데이터 분할 시 가장 좋은 속성을 선택하는 함수를 만들어야한다.
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) -1
baseEntopy = clacShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals =set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i , value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy+=prob*clacShannonEnt(subDataSet)
infoGain = baseEntopy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
위의 함수는 엔트로피를 계산하여 좋은 속성을 골라 리턴한다.
3.1.3 재귀적으로 트리 만들기
알고리즘 책에서 너무 많이 봐서 질리지만 아직도 잘 모르겠는 재귀에 대한 게 또 나온다..
트리는 자료구조에서 배우는 이진트리가 아니기 때문에 집합을 분할하는 방법이 두 가지보다 많다.
그래서 더 이상 분할할 속성이 없거나 하나의 가지에 이쓴 모든 사례가 전부 같은 분류항목 일때 재귀를 멈추게 할 것이다.
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel : {}}
del (labels[bestFeat])
featValues =[example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
두번 째 조건문에서 majority는 속성이 더 이상 없을 때 가장 많은 수를 반환하는 조건이다.

실행시켜 보면 딕셔너리 구조로 만들어진 트리가 출력된다.
다음에는 매스플롯라이브러리를 이용해 시각적인 트리를 플롯해볼 것이다.



댓글
댓글 쓰기